
6.824
6.824 Home Page: Spring 2018
6.824 Home Page: Spring 2018
https://pdos.csail.mit.edu/6.824/
6.5840 Home Page: Spring 2023
https://pdos.csail.mit.edu/6.5840/
Announcements:
Jan 25: Please use Piazza to read announcements and ask and answer questions about labs, lectures, and papers.
What is 6.5840 about?
6.5840 is a core 12-unit graduate subject with lectures, readings, programming labs, an optional project, a mid-term exam, and a final exam. It will present abstractions and implementation techniques for engineering distributed systems. Major topics include fault tolerance, replication, and consistency. Much of the class consists of studying and discussing case studies of distributed systems.
Prerequisites: 6.004 and one of 6.033 or 6.1810, or equivalent. Substantial programming experience will be helpful for the lab assignments.
MIT6.824分布式系统的正确食用方式(lab1.MapReduce) - 简书
https://www.jianshu.com/p/bfb4aee7a827
hello,我就以做lab1的流程为目录,记录一下我做lab1的时候收获的和容易出错的地方。
1.阅读MapReduce.2004论文,理解map reduce
2.了解go语言,使用git clone源代码
3.阅读源码,了解程序的执行流程
4.按步骤开始做实验
1.阅读MapReduce.2004论文,理解map reduce
关于map reduce,我认为主要关注以下几点。
a.是一种编程框架,将任务分解成多份,交给不同的机器执行
b.MapReduce将任务分为两部分来执行
[map阶段]:处理原始任务,产生包含"中间结果"的键值对的中间文件
[reduce阶段]:处理中间文件,产生包含最后结果的文件
*需要注意的是,这里的map和reduce是用户自定义函数。
c.框架共包含一个master和多个worker master负责给每一个worker分配任务,也负责管理每一个任务的状态。worker负责执行具体的任务,包括map和reduce。
下面这个图就描述的很清楚了。
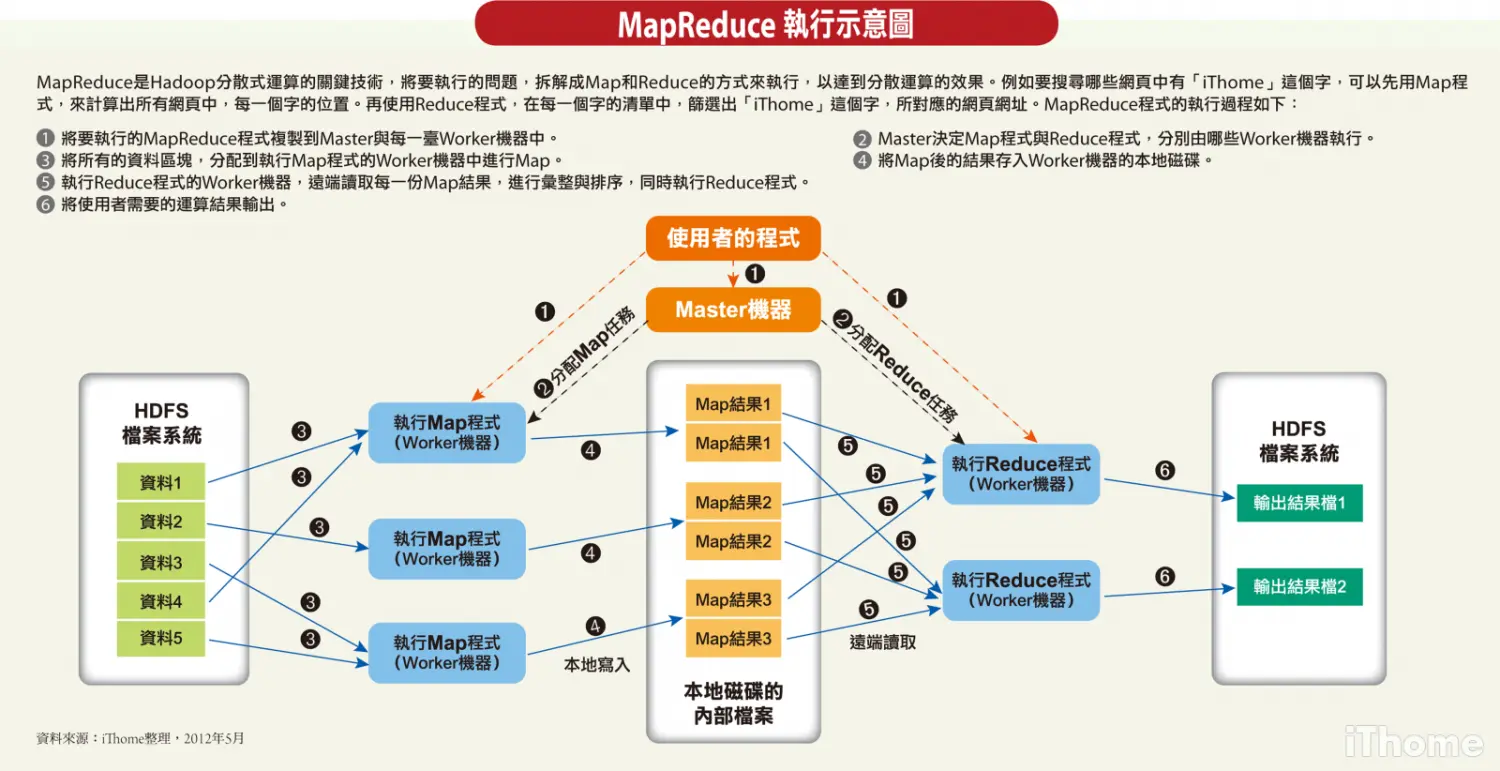
我就以实验一的word count举个例子来解释一下上面的图(word count就是算出一个长文章中每一个单词出现的次数)。
首先将任务分成5份,接着master将5个任务分别分配给3个worker,每一个执行map的worker会产生2个中间文件(这个2就是源码中nReduce,也就是执行reduce的worker的数量)。map产生的中间文件的内容是,("he","1") ; ("love","1")......这样的键值对,每一个单词都是1。接着reduce处理这些中间文件,将相同的单词的"1"加起来,得到每一个中间文件中每一个单词的个数,并产生一个输出结果文件。后面还会有一个merge函数会统计所有的输出结果文件。
2.了解go语言,使用git clone源代码
go语言还是挺好玩的,看看基本语法就能上手。我是看了这个《An Introduction to Programming in Go》http://www.golang-book.com/books/intro
不过go语言的一些强制特性还是挺讨厌的,比如导入的包必须使用,左括号不能单独占一行,if-else语句的else必须放在if的右大括号处,这些都会报错,调试起来还是很麻烦。
关于git呢,我是看的廖雪峰的git教程。
3.阅读源码,了解程序的执行流程
clone完源代码之后呢,有兴趣了解一下go语言的同学们可以看一看go的工作空间的设置http://www.kancloud.cn/kancloud/web-application-with-golang/44128
介绍流程前,我先说明一下大概的框架。我们要实现的mapreduce框架分为两个版本,一个是sequentia顺序版本,“顺序”说的是一个map任务执行完之后才执行下一个map任务,当所有的map任务执行完之后,才开始按“顺序执行”reduce任务。第二个是distributed版本,这个版本中,map任务是并发执行的,但也是执行完所有的map任务之后才去执行reduce任务。
流程是这样的,从wc.go中的main开始执行,接着执行master.go中的run,然后由run中的schedule来进行调度任务,在schedule中调用了框架的doMap和doReduce,其中又分别调用了用户定义的mapF和reduceF。其中顺序版本是顺序执行,并发版本是通过rpc来并发执行。
4.按步骤开始做实验
part1.
part1需要编写doMap和doReduce这两个函数,这两个函数是框架中的函数,不用考虑具体的事务。我说一下这两个函数的流程。
doMap,首先调用任务文件的内容为参数调用mapF,将结果存取键值对的数组(这里需要读文件,推荐ioutil库)。接着创建nReduce(nReduce在上面图片下面的讲解处)个中间文件,中间文件的名字使用reduceName(common_map.go)来产生。最后把键值对的内容存储到nReduce个文件中,那么有nReduce个文件,怎么知道把某一个key-value对存入到哪一个文件中呢。这里需要用ihash,我使用了如 int(ihash(x.Key))%nReduce 这样的代码,不知道有没有更好的办法。这里也要用到json库,查一查很简单。
doReduce,reduce的事情较多,我列出流程,方便理解。
1.找到属于自己的中间文件(这个可以参照图)
2.读出中间文件的每一个key/value对
3.sort,这里的sort指的是将相同的key/value对存入一个数组中,结果像这样{"he", "1", "1", "1"...}....(从doReduce函数的描述和mapF的参数得到的)
4.对每一个排序过的结果调用redeceF
5.使用mergername函数创建结果文件的名字,创建文件
6.将每个reduceF的结果写入到上一步产生的文件
*这个part是不用写mapF和reduceF的
part2.
这里就要写word count的mapF和reduceF,很简单就不说了。
part3.
前面的版本是顺序版本,这个part要实现并发的版本了,这里的并发是通过多个进程模拟的,不过也是通过rpc实现的,跟真实的情况还是很相近的。具体就不描述了,这里主要是运用这个registerChannel这个channel。注意到当有worker向master注册的时候,会向registerChannel发送消息,我们可以设计当某一个worker执行完之后也向这个registerChannel发送消息,这样程序的框架大概是这样
for{
str := <- mr.registerChannel
//分析str....
}
具体就不描述了,这个实验的乐趣就在这里了。我说一下我调试的方法,在关键点输出"@+信息",然后执行并将程序的输出重定向到文件中,再在文件中搜索"@"。
part4.
能做出前面的话,这里就不成问题了。我这里在加锁解锁方面出了问题,调试了很久。





发表评论